Persistent GenAI Hub
Create GenAI experiences quickly, efficiently, and responsibly

Create GenAI experiences quickly, efficiently, and responsibly
Enterprises want to take advantage of Generative AI’s immense potential — but they must do so quickly and don’t want to start from scratch. Companies want to layer in and integrate new AI-powered capabilities across previous investments, assets, and functions such as data, infrastructure, applications, analytics, and customer support for fully GenAI-enabled services.
To accelerate GenAI-powered enterprise transformation, we’ve developed the Persistent GenAI Hub so companies can create faster, more efficient, and secure GenAI experiences at scale, anchored by the principles of Responsible AI. Enterprises can adopt GenAI across different large language models (LLMs) and clouds, with no provider lock-in, integrated with existing assets and enabled by pre-built accelerators. With the Persistent GenAI Hub, enterprises have a complete platform and roadmap for accelerated GenAI adoption and faster go-to-market for new AI-powered services.
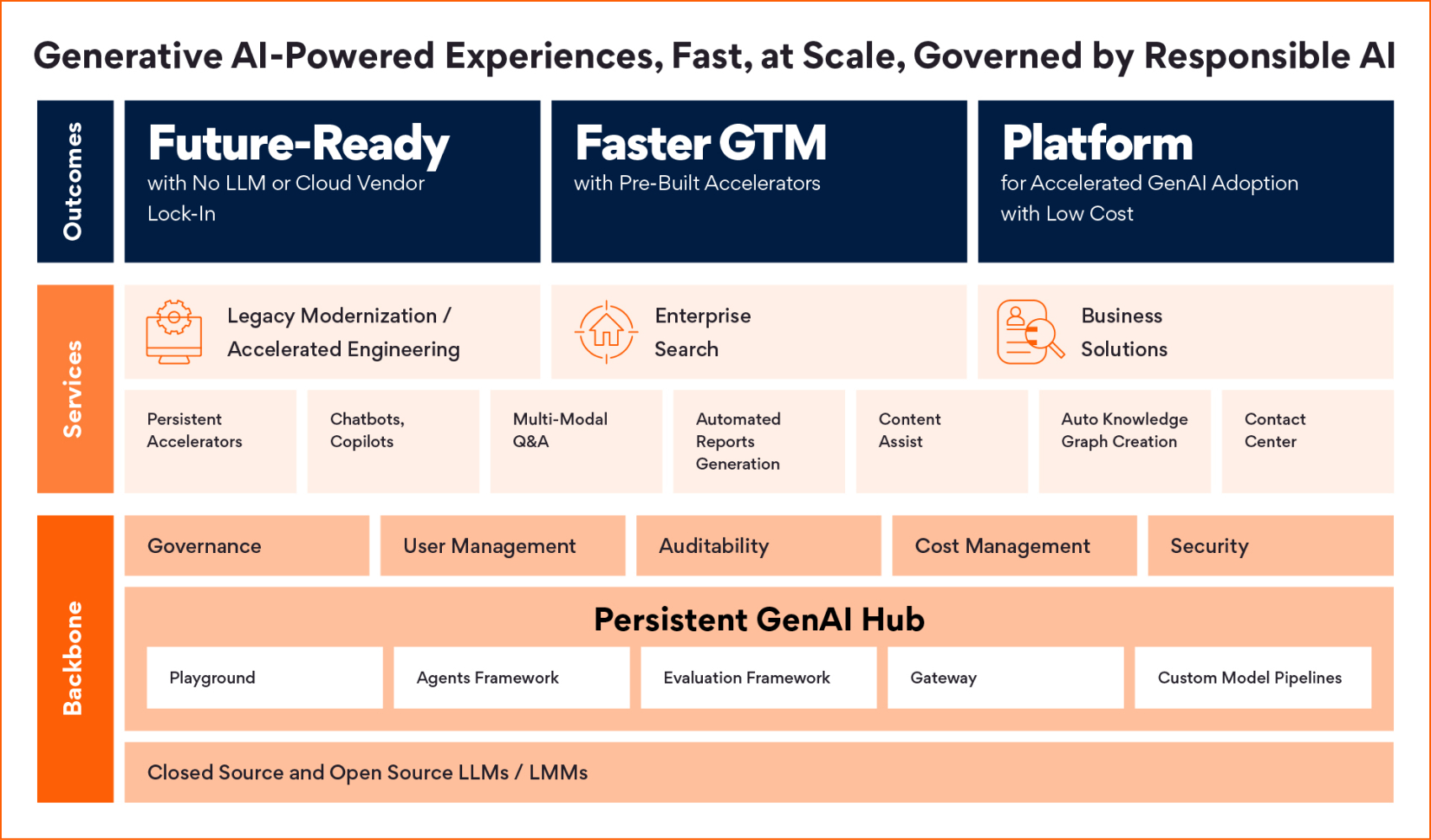
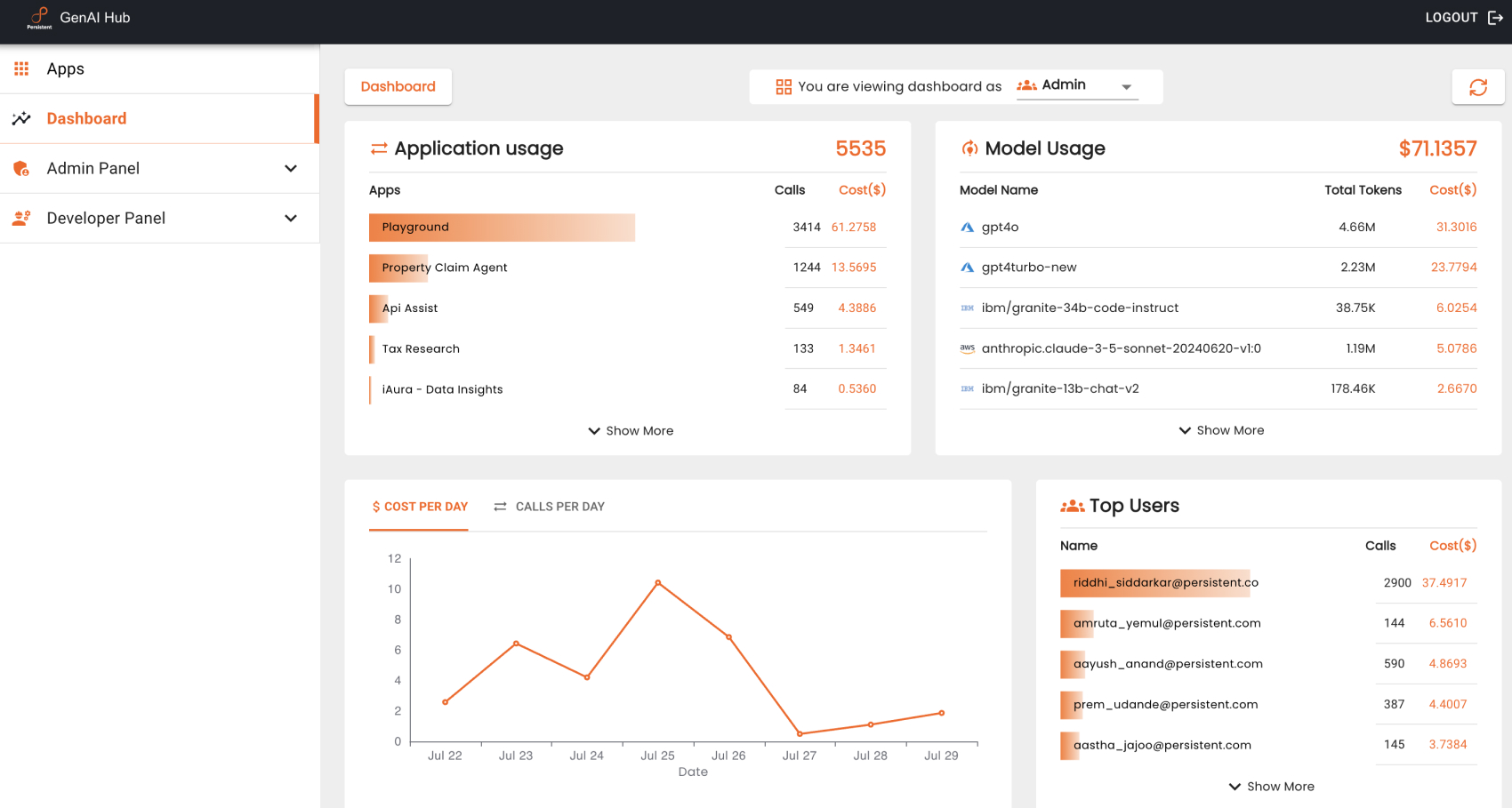
Playground is a no-code tool for domain experts to conduct GenAI experiments with large language models (LLMs) on enterprise data. It provides a single uniform interface to LLMs from private providers like Azure OpenAI, AWS Bedrock, and Google Gemini, and open models from Hugging Face like LLaMA2 and Mistral. Playground includes connectors to popular data sources like Vector, SQL, and Graph databases, and a Prompt Library to store and reuse domain-specific prompts.
Agents Framework is built on best-in-class open LLM application libraries like LangChain and LlamaIndex and provides GenAI developers an agile way to build applications following patterns like Retrieval Augmented Generation (RAG). For advanced use cases, agents can assist with building applications that automate reasoning and dynamically solve problems using a pre-defined library of tools.
Any application deployed on GenAI Hub has in-built access to an Evaluation Framework that brings together best-in-class patterns and metrics to validate GenAI applications like RAG. This framework uses an “AI to validate AI” approach and can auto-generate ground-truth questions to be verified by a human-in-the-loop. Metrics can be run on each upgrade to attain true observability of LLM application performance, as well a measure of any drift and bias that can be addressed.

Adopt an accelerated “GenAI First” strategy for your enterprise

Take the guesswork out of GenAI solution development

Deliver new GenAI-powered applications and services to end users, customers, and employees

Develop standard blueprints for developing GenAI applications across your enterprise

Practice Responsible AI while quickly developing GenAI-powered applications

Innovate with our pre-built accelerators and evaluation frameworks to monitor and measure success

Leverage multiple LLMs and automatically take advantage of cost optimization strategies by matching the most cost-effective LLM to specific use cases

Quickly prioritize and optimize dynamic LLM pricing by directing specific applications toward better-priced LLMs without re-prompting or re-coding

(*) Asterisk denotes mandatory fields