
Genomics data is known for its significant volume, heterogeneity and different formats that pose a huge challenge for interoperability. Given the crucial information inherent to genomics data, it serves a broad audience ranging from physicians, researchers, and clinicians to patients. The genomics information undergoes necessary transformation to cater to consumer needs and hence there is a need for a standard model that enables seamless sharing of genomics data across diverse portfolios and organizations.
Fast Healthcare Interoperability Resources (FHIR) genomics is an evolving HL7 standard to create an interoperable format for Next Generation Sequencing (NGS) data. FHIR adopts a modular approach to collect and store various types of healthcare data , including patient details, clinical information, or observation, drug and treatment. Each FHIR resource adheres to a standard format that includes some unique identifier(s) and a defined set of elements for collecting and representing the data.
FHIR genomics has additional resources and profiles to help accommodate molecular details and characteristics that can be mapped to other FHIR structures like patient details or treatment details. In this context, we discuss the usage of FHIR genomics implementation in pre-built automated data analysis pipelines to enable easy access to genomics data for clinical and pharmaceutical researchers.

FHIR Components
FHIR constitutes a set of components that play together to create a standard format for structured and unstructured data. A quick glimpse of the main FHIR components –
Resources are the basic building blocks of FHIR and help in building the main elements like patient, medication, diagnostic report, etc. Resources are designed as self-contained pieces of information that can act as connectors between other FHIR elements.
Profiles allow us to define and customize the contents of FHIR resources.
References help to connect or refer one resource to another.
Terminology is about different standard codes such as SNOMED and LOINC which are used by FHIR to ensure that the data is consistent and unique between different healthcare information systems.
RESTful APIs allow developers to send and receive data using HTTP requests. Additionally, it helps to integrate FHIR with existing systems. FHIR also includes several security features, like OAuth 2.0 authentication and SSL/TLS encryption, to ensure that healthcare information is protected and secure and follows standard data compliances.
FHIR Framework, Tools and Platforms
FHIR provides flexibility in implementation and can be customized to match the healthcare organization’s requirements:
- FHIR client helps to consume FHIR resources from FHIR server
- FHIR server is a software application that provides FHIR resources to FHIR clients
- FHIR interface engine is a software application layer that helps to connect different healthcare systems and applications
- FHIR extensions are the customizations to the FHIR standard created by individual organizations or communities. These extensions can be used to add new functionality or data
There are multiple FHIR tools and platforms developed by the community to help in resource building, validation and storage. These are highly resourceful when an organization wants to store its data in FHIR standards. HAPI FHIR is a community-developed open platform in Java and has complete implementation of the HL7 FHIR standards. FHIR validator is a web-based as well as CLI-based application that validates newly created FHIR resource. FHIR services are also available on the leading hyperscalers such as FHIR Server for Azure, FHIR Works on AWS and Google Cloud FHIR. Also, there are communities like EPIC and Confluence that are actively working on developing FHIR resources for a multitude of applications and making FHIR accessible to users.
Genomics Data on FHIR
Schema and Hierarchy
The standard output format in DNASeq analysis pipelines is a VCF file. The VCF file contains all the variant details such as location, reference allele, alternate allele, data quality, clinical significance, variant classes, consequences, etc. These details are critical in variant interpretation and are valuable to both clinicians and researchers in designing clinical diagnostics, trials and treatments. Figure 2 below depicts our FHIR schema to map the patient detail to variant details and diagnostic report. In the Genomic Report schema, major sections are represented in solid-filled yellow color.
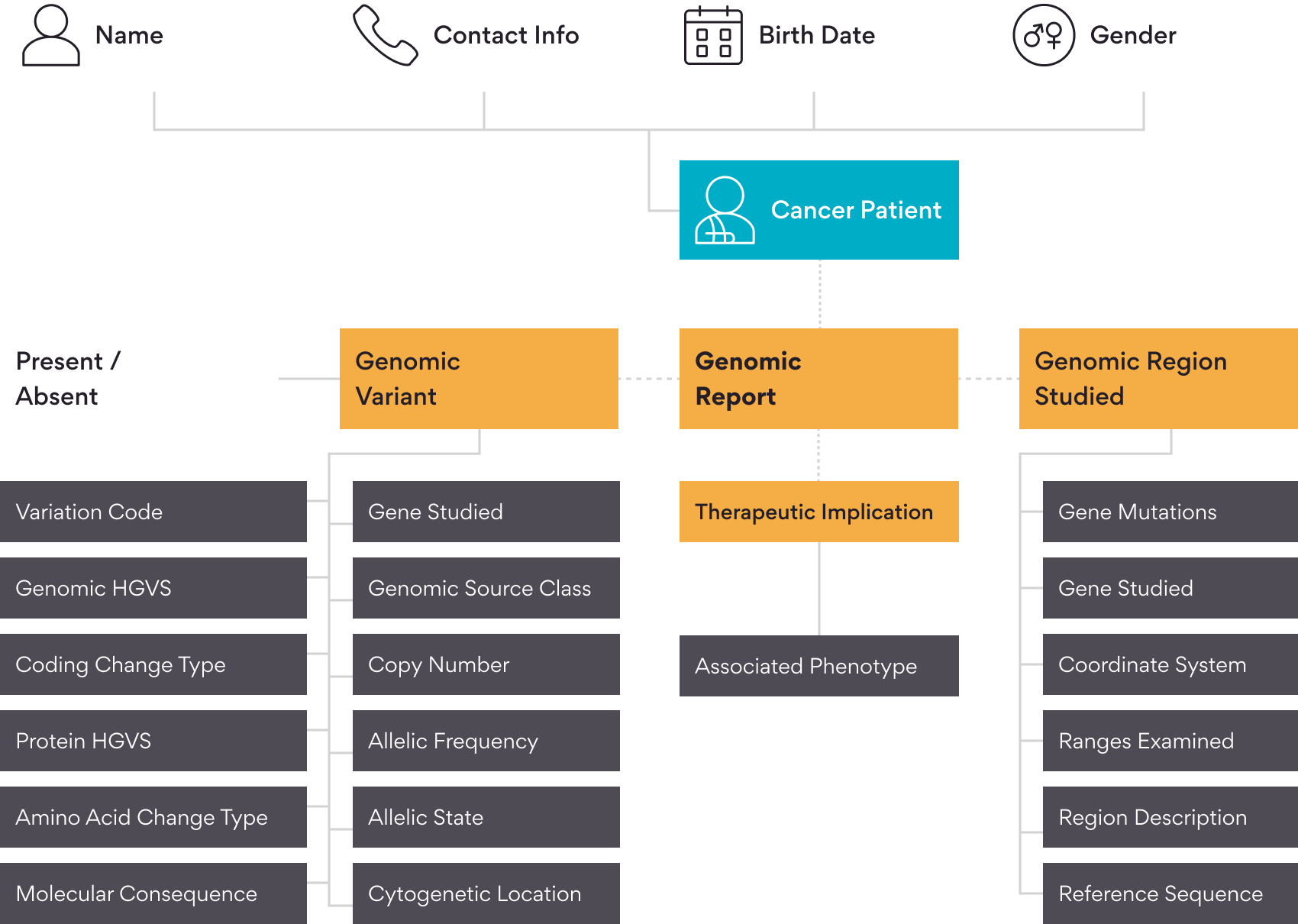
Workflow
In this section, we brief the workflow for converting the variant fields from genomics data to FHIR resources
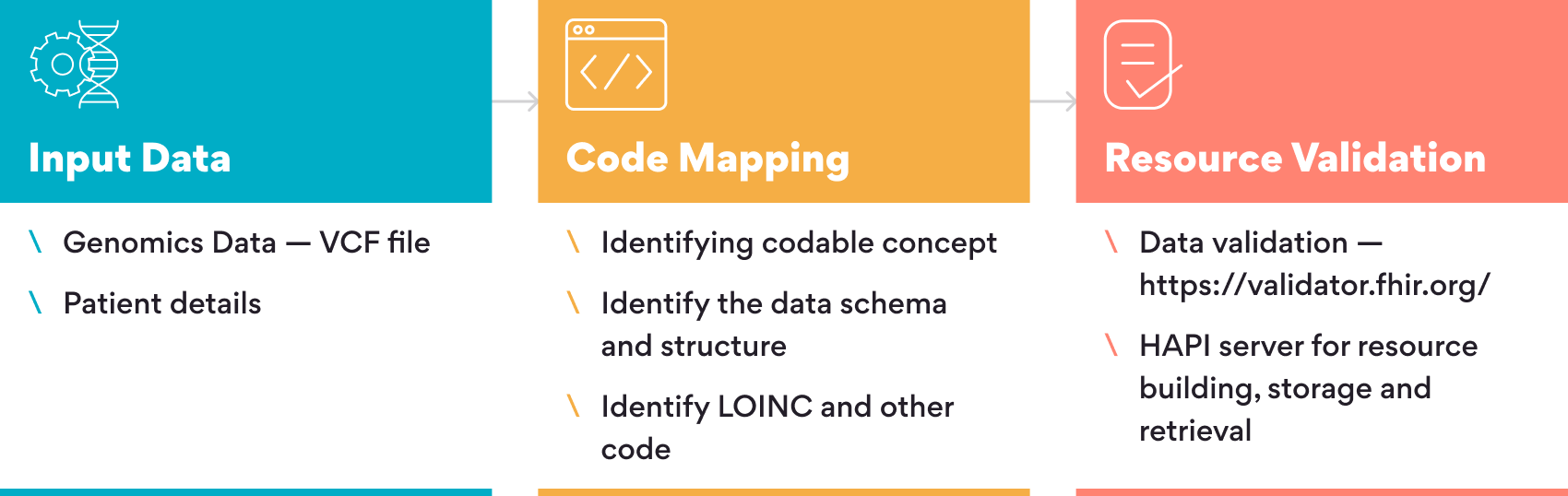
- Identify the FHIR supported entities from VCF file
- Identify the data schema and structure for those fields (Genomics Reporting Implementation Guide )
- Identify the standard codes for data representation and interoperability (LOINC, Sequence Ontology, etc.) For example, the reference and alternate allele for a given variant can be added using the FHIR Observation Component “component:ref-allele” and “component:alt-allele” and their respective LOINC codes 69547-8 and 69551-0
- Validate the FHIR resources using a FHIR validator
- Store and retrieve data using HAPI server APIs
Improving Healthcare Data Interoperability with FHIR
FHIR has been leading the data standards for interoperability. Given the wide applications of genomics data in healthcare, it is imperative to have a system that enables standardization in this field. FHIR allows customization as per the use cases without compromising the core standards.
Better Clinical Treatment and Patient Experience
The easy access to patient-related data such as EMR, diagnostics reports, and treatments will allow the system to monitor the patient progress in an effective manner. This saves time and cost involved in patient diagnosis and treatment and also creates a bridge to enable faster analysis and decision-making.
Payer and Provider Collaboration
FHIR can help the payer and provider in sharing data, which can help in better care coordination, data management and prevention.
Data Management
FHIR can help to collect and maintain error-proof data from different systems. The FHIR standards assure data accuracy in all stages.
FHIR for Specific Use-Case
FHIR standards offer the flexibility for customization to adapt to new data requirements. Organizations can construct their own data structures tailored to cater to their proprietary data needs. FHIR has created a translational bridge that enables crosstalk between research-based genomics data and clinical information. With its ease of integration into any application, it has significantly streamlined sensitive data sharing without compromising its security. However, it is important to exercise caution, as the FHIR standards are highly version-sensitive in this rapidly evolving field.
Life sciences experts at Persistent can help you bring interoperability to your healthcare data and build FIHR sources. With our extensive knowledge and experience in technology and understanding of complex biological data, we are uniquely positioned to assist organizations in maximizing their productivity by implementing our tailored solutions. Persistent’s multi-cloud based automated Multi-omics data analysis platform with custom technical environment empowers researchers and translational scientists in biomarker prediction, drug target prioritization, and patient stratification and helps them gain deeper insights into complex data sets.














