Persistent GenAI Hub
Create and manage multi agent workflows with guardrails, tools and evaluation

Create and manage multi agent workflows with guardrails, tools and evaluation
Enterprises know the power of Generative AI but turning that potential into reality can feel like navigating a maze. Building from scratch is slow and costly, and integrating AI into existing data, applications, and customer services is complex.
Persistent GenAI Hub makes that journey easier. It is a Responsible AI driven platform that enables organizations to experiment across multiple LLMs securely, scale and monitor AI Applications.
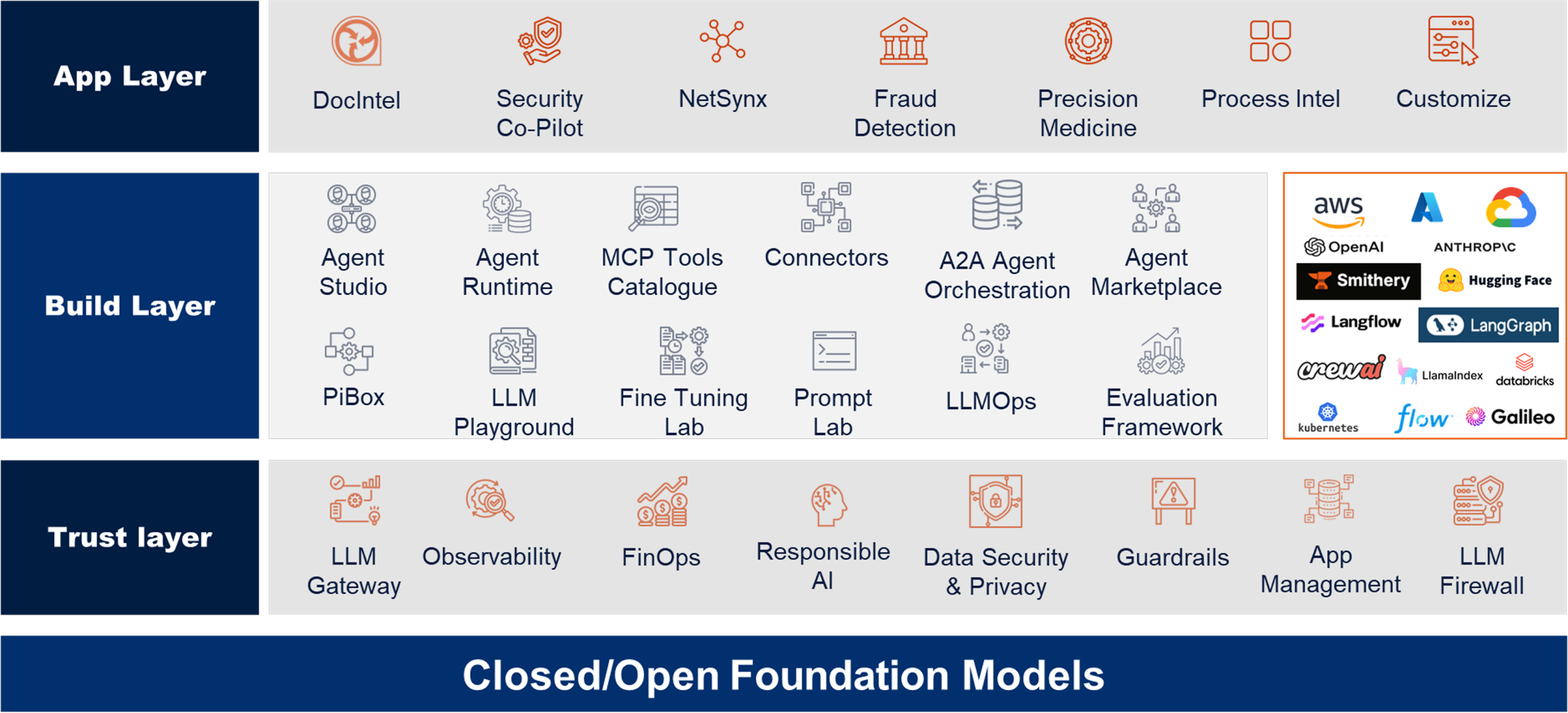
Functional Layered View
As Agentic AI is reshaping the world with autonomous decision-making to drive transformative actions across industries, we have built Agent Studio – a no code platform to help business users build AI Agents. Agent Studio along with GenAI Hub helps organizations adopt Agentic AI at scale.
Agent Studio is an enterprise-grade, no-code platform that empowers business users and subject matter experts to design, manage, and orchestrate AI agents efficiently. Leveraging the GenAI Hub ecosystem, it combines speed, scalability, and simplicity with enterprise-level security and compliance.
Eliminates complexity for business users.
Leverage reusable MCP tools for speed.
Flexible, no-code interface for easy design.

AI-native, agentic data platform that standardizes and automates data operations while accelerating AI readiness across hyperscaler and enterprise environments.
Business Value

LLM-powered intelligent document processing platform delivering enterprise-scale automation for document classification, extraction, and authoring.
Business Value

An Agentic AI accelerator that transforms business processes to agentic AI workflows that consists of multi-agent reasoning to optimize workflows, augment decisions, and autonomously execute context-aware business actions.
Business Value

AI-driven cybersecurity assistant combining LLM-based log intelligence with agentic decision-making to accelerate threat detection, investigation, and response.
Business Value

Centralized threat intelligence knowledge graph unifying vulnerabilities, assets, and timelines to enable root-cause analysis and informed mitigation planning.
Business Value

GenAI-powered adaptive experience layer that personalizes content, layout, and functionality based on user context and real-time interaction signals.
Business Value

LLM-based insight engine that curates, synthesizes, and generates personalized security and GenAI newsletters from large-scale unstructured sources.
Business Value

Innovation-as-a-Service platform enabling structured ideation, enterprise hackathons, and co-innovation through secure sandboxes and integrated tooling.
Business Value

GenAI-powered document intelligence platform automating ingestion, comparison, analysis, and compliance validation across regulated environments.
Business Value

Adopt an accelerated “GenAI First” strategy. Scale new GenAI-powered applications and services in a faster, efficient and secure manner.

Quickly create agents enabling responsible, vendor-agnostic, and optimized agentic AI adoption.

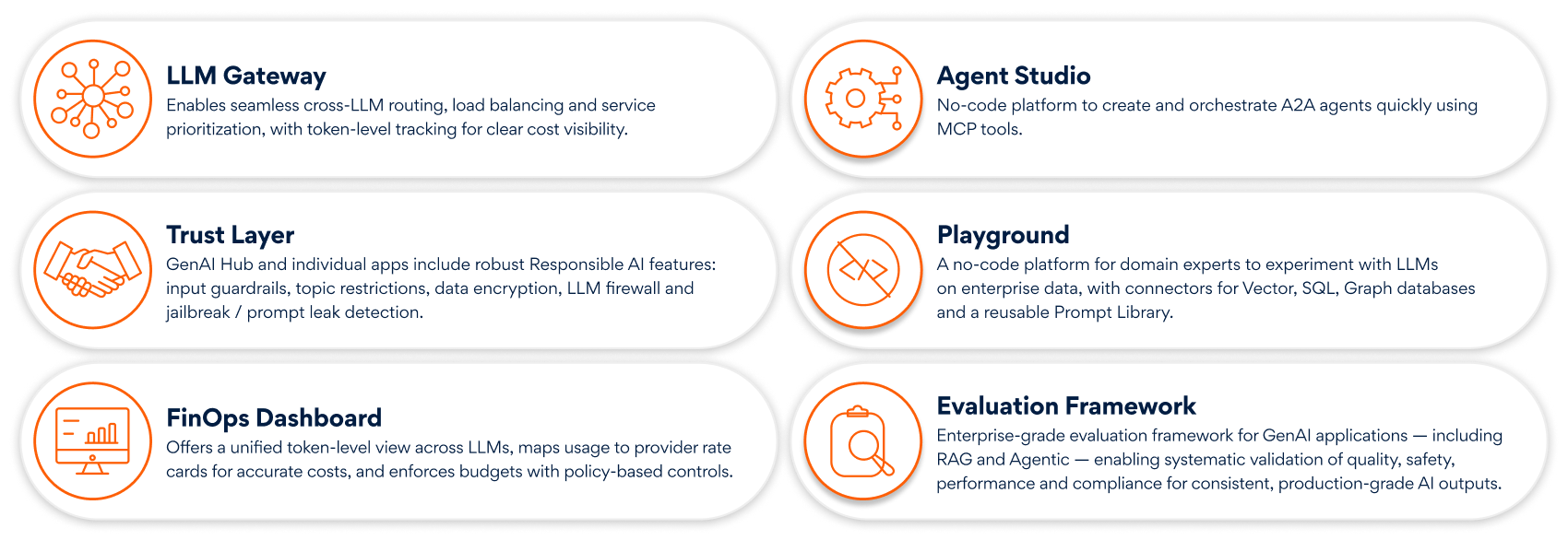
Get multi-LLM support, cost tracking, and an evaluation framework for RAG Applications and Agents.

Delivers granular observability at application and user level for prompts and agent-LLM interactions and FinOps-driven cost management with dashboards.

It has a robust trust layer ensuring responsible AI, security, and compliance—while the build layer accelerates agent creation and experimentation for rapid innovation.

Leverage evaluation framework to monitor and measure application performance.
Bringing together the best of our partner network to create competitive advantage for your business.

(*) Asterisk denotes mandatory fields