
Snowflake revolutionized the data warehousing industry with the launch of its cloud offering in 2014. They introduced and successfully implemented the concept of storage and compute separation in the data warehousing world. Plus, they effectively leveraged cloud by providing elasticity in usage and costs. Snowflake has for the most part remained a very SQL heavy transformations system. However, that has undergone a change since they introduced their Snowpark offering last year.
Snowpark – The new data transformation ecosystem
Snowpark allows developers to write transformation and machine learning code in a spark-like fashion using python (or java) and run the code on Snowflake’s virtual warehouses i.e. “without” the need to maintain or to provision any separate additional compute infrastructure.
It is very similar to Spark with the fundamental difference of not requiring a separate compute infrastructure. That’s what Snowflake is banking on. It is Anaconda powered and runs within Snowflake Anaconda powered sandbox in its virtual warehouse.
See below for a 30,000 feet comparison between Spark and Snowpark.
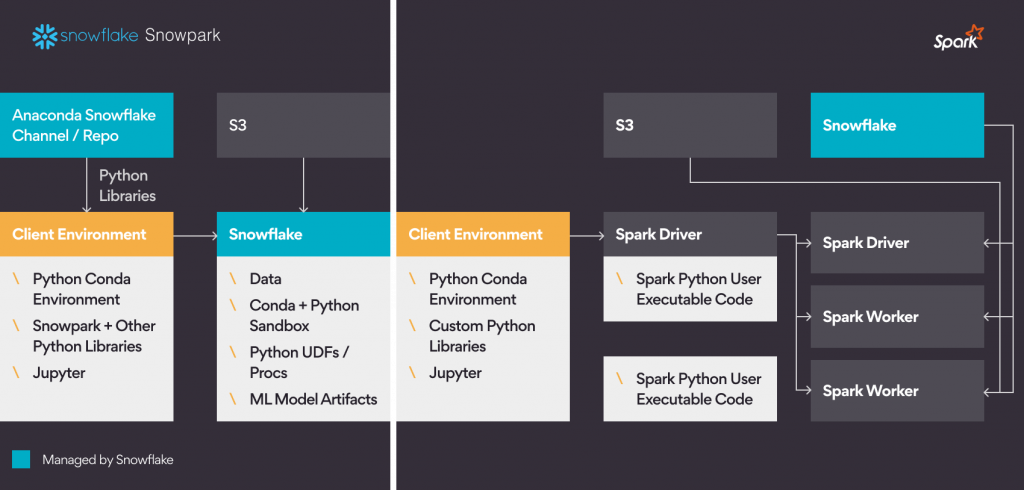
Snowpark provides a client API to developers that can be used with Python, Scala, Java to perform transformations. It works on lazy execution principles like Spark. You can use Jupyter to write and debug Snowpark programs.
For Data Science workloads you can now do preprocessing, feature engineering, model training, and model execution all using the Snowpark API. The best part is that all execution happens within Snowflake virtual warehouses. No additional compute or configuration or maintenance is needed.
Snowpark seems to provide some clear-cut advantages over traditional transformation technologies like Spark, Hadoop, DBT. Listing some of the important ones below –
- Zero cluster maintenance: Other than Snowflake, no additional service or infrastructure is needed. That means unlimited scalability and flexibility with near zero maintenance. No extra compute technology is needed.
- Inherently secure: All processing happens within Snowflake. Data does not leave Snowflake.
- Multi use case support: SQL based, or non sql based Data Pipelines, all supported using Snowpark. Support for unstructured, semi-structured and structured data by leveraging different Snowflake engine’s powerful UDF features.
- Opensource package manager: Full python support and access to open-source packages and package manager via the Anaconda integration. No additional setup required.
- Governance friendly: As everything happens within Snowflake, its easy to enforce governance policies from the single Snowpark+ Snowflake platform. No redundancy, no unwanted network access, no data movement outside Snowflake.
- Multi language support: Other than SQL it supports the top programming languages viz Python, Java and Scala.
- Free API with Snowflake subscription: No additional charge for using Snowpark.
- Data scientist friendly: ETL developers, Data Scientists will now all be working on the same platform bringing homogeneity and predictability in the process. Devops becomes simple and worry free.
SQL Transformations Vs Snowpark – A perspective on when to use one over the other
With all this cool stuff going around the question to answer is – should enterprises completely migrate to Snowpark? The simplicity provided for standard SQL transformations (stream, tasks, stored procedures or DBT based transformation) is too lucrative to completely ignore. Data engineers should leverage both SQL transformations and Snowpark while building data pipelines.
Here are some thumb rules on when to use SQL transformations Vs Snowpark
| Type of Transformations | SQL Transformation | Snowpark |
| Parsing | Standard formats like CSV, JSON, Parquet are easy to parse and process using standard SQL | Easy to parse EDI, IOT type formats. |
| Translation and Mapping | Source to target mapping is easy | Might get complex for simple mappings |
| Filtering, Aggregation, Summarization | Good support for filtering, aggregation, and summarization functions available. | Good support here too. |
| Enrichment and Imputation | Would be complex to achieve | Python over Snowpark scores much better in this area |
| Indexing and Ordering | SQL has very rich functionality and can be leveraged easily | Python is at par |
| Anonymization and Encryption | May not be available | Python third party libraries can be used |
| Modeling, typecasting, formatting, and renaming | Ease of use when converting to standardized data models (e.g., dimensional model, Data vault) | Might be complex using this. |
| Model execution/inference | The models need be implemented as UDFs to execute them through SQL. This might get complicated. | Python/Snowpark scores much better for model execution |
| Model training | SQL does not have any such capability | Snowpark shines here due to full python support |
To summarize, Snowpark is a new technology, and its adoption by Snowflake customers and the technology community is still to reach maturity. Also, it needs to prove its mettle on a production scale. It has a steep way ahead to get its head over to incumbents like Databricks, Hadoop, and other such transformations technologies. However, it’s a new age, cool solution and for users who are on Snowflake, it is an interesting option to try out. Remember that it’s from Snowflake and they do have a powerful team behind their cloud platform. So go try it!
In the second part of this blog series, we will cover some important functionalities provided by the Snowpark API and see them in action.





