
The Elastic Search, Logstash, and Kibana stack (ELK) is a very popular stack for log analysis. While this stack is very effective for real-time log analytics, it is not a cost-effective solution for storing and querying historical data over several years. Also gaining popularity now is Snowflake, a cloud data warehouse with JSON support. How would it work as an augmentation to the ELK stack? The team at Persistent set out to answer that question in the hopes that it would prove to be a strong, cost-effective solution.
This blog introduces Snowflake as a data backup solution for ELK data. It includes an explanation of how to set up a pipe between Logstash and Snowflake. We will also go over some performance numbers and costing before we give you our verdict.
ELK Stack Augmentation with Snowflake
Typically, data is ingested into Elastic Search using Logstash. Our approach entails adding a separate pipe from Logstash to Snowflake, as below.
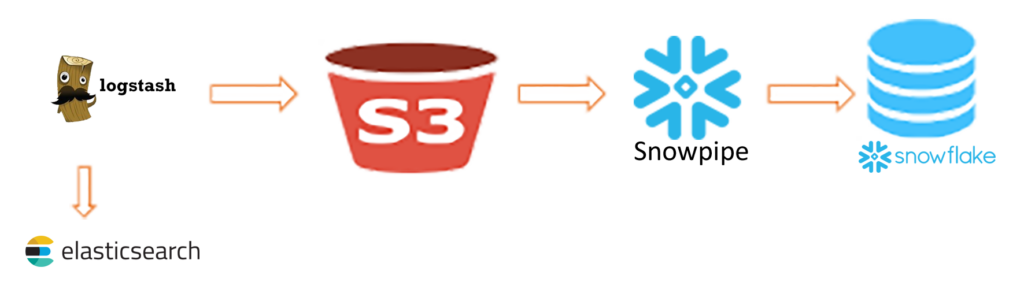
This is done to make the data available within both Elastic Search and Snowflake. ELK can be used for real-time data analytics, which involves full text search as well. The data in Elastic Search can be purged so that it only maintains data from the previous week or month. Historical data analytics can then take place on Snowflake.
Why Snowflake
Snowflake stands out among other Massively Parallel Processing (MPP) database technologies for its:
- First class JSON support
- Storage compute separation
- Unlimited scalability
- Pay-as-you-go model (and pay only for what you query rather than for how much you store)
- Fully-managed service
- Excellent support for the continuous ingestion of data
Continuous Ingestion into Snowflake
Traditional databases cannot make use of continuous data. They require a batch-oriented approach, which involves the loading and scheduling of jobs. Here’s what that looks like:

In the traditional way of loading data into a Data Warehouse, data that is generated continuously is accumulated and then loaded in batches daily or hourly. This approach renders data stale because it is not available as soon as it is generated.
Snowpipe is Snowflake’s continuous data ingestion service. Snowpipe loads data within minutes after files are added to a stage and submitted for ingestion. The service provides REST endpoints and uses Snowflake-provided compute resources to load data and retrieve load history reports. Snowflake manages the load capacity, ensuring that optimal compute resources are used to meet demand. Data can be loaded in micro-batches, making it available within minutes as opposed to manually executing copy commands on a regular schedule to load larger batches of data.
Setting up Logstash to push data into Snowflake
Logstash is server-side data processing pipeline that ingests data from multiple sources. The data can be synched into Amazon S3. Then, Snowpipe can be used to send data from S3 to Snowflake. Below is Logstash configuration file that we have used in the code.

Setting up Snowpipe to load data from S3 to Snowflake
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers scalability, data availability, security, and performance. Before it can be used here, we will need to configure S3 event notifications for Amazon S3 Bucket.
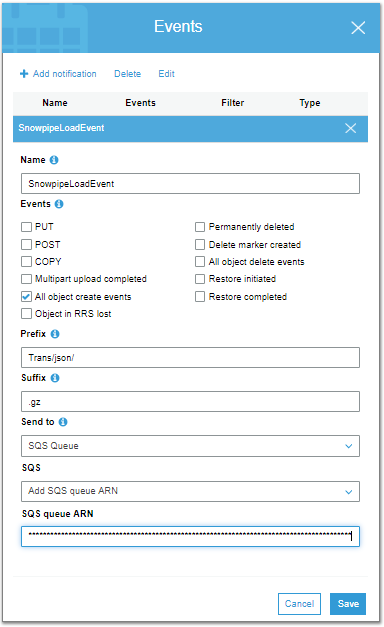

Whenever new data files are discovered in the external stage(S3 bucket), they are queued for loading. Snowflake-provided compute resources load data from the queue into a Snowflake table based on parameters defined in the pipe.
A pipe is a named Snowflake object that contains a COPY statement used by the Snowpipe REST service.
The COPY statement identifies the source location of the data files (i.e., a stage) and a target table. All data types are supported, including semi-structured data types such as JSON and Avro.
Snowpipe and COPY Command store different metadata for each file loaded in Snowflake. Snowpipe works as a wrapper around the COPY Command with auto_ingest = “true”.
| COPY Command | Snowpipe | |
|---|---|---|
| Authentication | Traditional username/password authentication. | When calling the REST endpoints: Keypair-based authentication with JSON Web Token (JWT). JWTs are signed using a public/private key pair with RSA encryption. |
| Transactions | Adds data to a table in transactions alongside any other SQL statements submitted manually by users. | Adds data to a table in transactions controlled by Snowflake with no opportunity to involve other statements in the transaction. |
| Load History | Stored in the metadata for the target table. Available upon completion of the COPY statement as statement results. | Stored in the metadata for the pipe. Must be requested from Snowflake (via a REST endpoint, SQL table function, or ACCOUNT_USAGE view). |
| Compute Resources | Requires a user-specified warehouse to execute COPY statements. | Uses Snowflake-supplied compute resources. |
| Cost | Billed for the amount of time each virtual warehouse is active. | Billed according to the compute resources used in the Snowpipe warehouse while loading the files. |
To setup Snowpipe with an auto ingest feature, it needs to be enabled explicitly at the account level.
Data Load Experiment:
We used a dataset consisting of 55M records for our experiment.
- Source Data
-
- The source data is dummy transaction data. The format of each JSON record is shown below.
{
“guid”: “80f58b7f-2f78-4449-91dd-2c0ec27240ff”,
“isActive”: “False”,
“balance”: “2,041.615”,
“picture”: “http://placehold.it/32×32“,
“age”: “29”,
“eyeColor”: “green”,
“name”: “Travis Singleton”,
“gender”: “male”,
“company”: “ONTAGENE”,
“email”: “travissingleton@ontagene.com“,
“phone”: “+1 (825) 403-3922”,
“address”: “496 Grand Street, Mulberry, Florida, 3105”,
“about”: “Nostrud eu do cupidatat cillum aute aliqua. Non id duis cupidatat occaecat aute aute fugiat. Sit aliqua culpa sunt officia esse anim duis. \r\n”,
“registered”: “2015-03-14T06:54:51 -06:-30”,
“latitude”: “-4.092909”,
“longitude”: “-86.060673”,
“greeting”: “Hello, Travis Singleton! You have 6 unread messages.”,
“favoriteFruit”: “strawberry”
-
- file has been split into 557 gzip files. Total file size is around 6.62GB.
2. Snowpipe configuration
-
- Added an event to S3 Bucket on file upload in S3 Bucket, which notifies Snowflake SQS, and in turn it triggers the execution of Snowpipe.
3. Loaded JSON files sequentially into S3 Bucket.
4. The bucket notifies Snowflake SQS about a file being available and in turn it triggers the execution of Snowpipe which loads data from S3 Bucket to the Snowflake table.
5. Created view to read data from the table (JSON format).
6. Row count of the Snowflake table is ~55M.
7. Average load time from S3 to the Snowflake Table is 35 seconds.
SELECT COUNT(*),MIN(TIMEDIFF(SECONDS,PIPE_RECEIVED_TIME,LAST_LOAD_TIME)) MIN_TIME_DIFF,
MAX(TIMEDIFF(SECONDS,PIPE_RECEIVED_TIME,LAST_LOAD_TIME)) MAX_TIME_DIFF,
AVG(TIMEDIFF(SECONDS,PIPE_RECEIVED_TIME,LAST_LOAD_TIME)) AVG_TIME_DIFF
FROM ( SELECT * FROM TABLE(INFORMATION_SCHEMA.COPY_HISTORY(TABLE_NAME=>’TX_DATA_SNOWPIPE’, START_TIME=> DATEADD(DAYS, -2, CURRENT_TIMESTAMP()))));
| Total files | Minimum Time to process file (seconds) |
Maximum Time to process file (seconds) |
Average Time to process files. (seconds) |
|---|---|---|---|
| 557 | 12 | 65 | 35.023 |
8. All analytical queries finish in < 1 second on SMALL Warehouse, except when the cache is not warmed up.
There is no lag in the process of Snowpipe consuming data from S3. Maximum lag observed is 3 minutes.
Pricing
With Snowpipe’s serverless compute model, users can initiate a load of any size without managing a virtual Warehouse. Accounts are charged based on actual compute resource usage. Read this to gain an understanding of billing for Snowpipe usage.
Conclusion
We concluded that Snowflake can provide great augmentation to the ELK stack for storing historical data. Our opinion is that the Snowflake architecture model, pricing model and high-performance JSON querying support is very attractive for such an augmentation mode.





