
In the ever-evolving landscape of data platforms, one pattern that is gaining rapid acceptance as a modern approach is the “Lakehouse pattern,” centered around the powerful Delta Lake. At Persistent, we’ve been actively collaborating with numerous customers, assisting them in constructing robust data platforms based on this revolutionary pattern.
I have aligned the best practices to the following high-level areas – Operation Excellence, Reliability, Performance and Cost Optimization and Security. I discussed the best practices in the areas of Operation Excellence, Reliability in the Best Practices for Data Engineering with Databricks Part I of this two-part series, I highly encourage you to read the same. In this second installments, I will cover the best practices around the performance and cost optimization and security aspects.
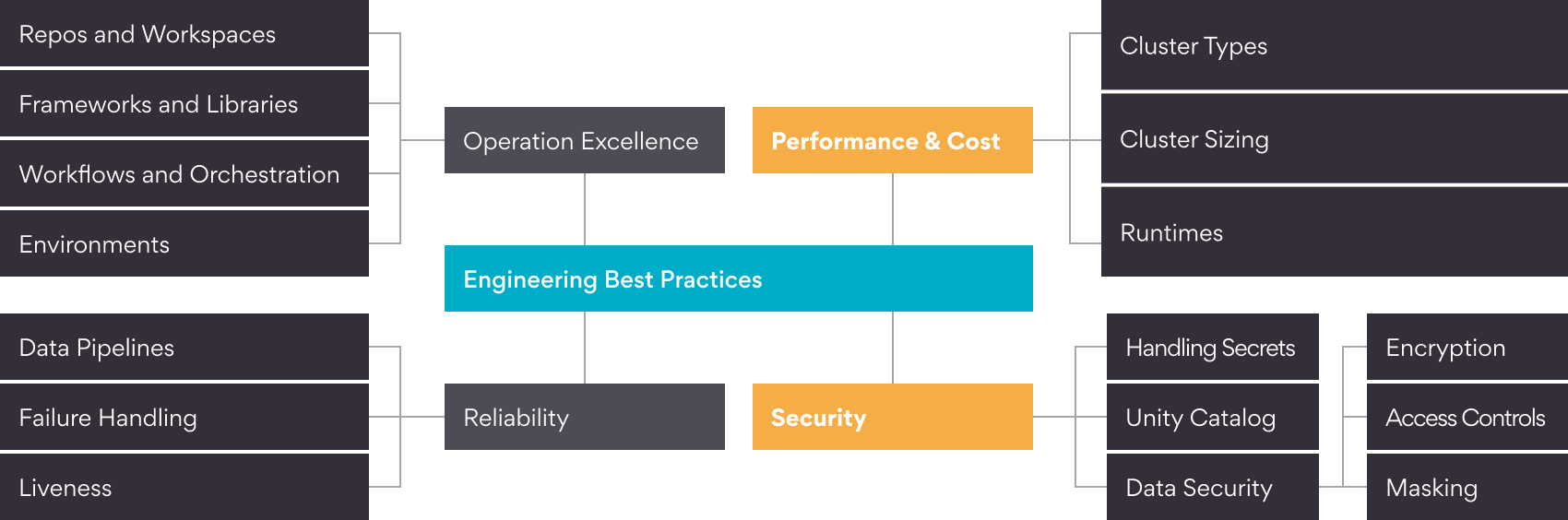
As with the Part I, I will assume the implementation of a Data Lakehouse on AWS, using S3 as the storage solution and Databricks as the compute engine. However, these best practices can also be applied in scenarios not limited to AWS and Databricks.
Optimize for Performance and Cost
Right size your job clusters
In a typical data platform, multiple Databricks jobs will be built over a period and it’s not uncommon for developers to continue using the same cluster configuration for different pipelines like simple ETL, complex ETL, analytical workloads, etc. This often occurs due to developers primarily focusing on problem-solving and lacking awareness of other aspects. Imagine you have multiple projects running hundreds of job clusters; even a minor optimization in job runtime by a few minutes can result in a lot of savings. Encourage and educate developers on right-sizing the job clusters, effectively using optimizations like Graviton-enabled, GPU-enabled clusters, and photon runtime to optimize their workloads and costs.
Keep your Databricks runtimes updated
Databricks releases new runtimes frequently, often with new Spark versions, features, and optimizations. Take advantage of this and update your Databricks Jobs to utilize the latest Databricks Runtimes. Often once a data pipeline is built and the project is handed over to the ops team, the Databricks jobs are not touched unless there is a production defect. Encourage the teams and set up a process to review the Runtime configuration for Databricks jobs periodically and upgrade the same rather than waiting till the end-of-support for a particular Databricks runtime.
Do not over-optimize
Optimizing cost and performance is a common goal for everyone. When working with delta tables in Databricks, there are built-in methods to optimize storage usage, such as the VACUUM command. By default, the VACUUM command retains data for 168 hours and removes anything older than that. However, it’s important to note that some teams have been overly aggressive in their optimization attempts by using the RETAIN 0 HOURS parameter. While Databricks advises against this practice, there are specific scenarios where it might be necessary, such as when working with tables exposed through Athena as Parquet tables or when dealing with legacy tables that are now being built using Databricks.
Nevertheless, I firmly advise against using the RETAIN 0 HOURS parameter. Instead, an alternative approach is to convert the Athena tables to use Symlink. Consider a situation where a consumer application is reading version 230 of a table while another application is updating the table to create version 231. If the writer application finishes before the consumer application and executes a VACUUM command with RETAIN 0 HOURS, the consumer application will encounter a FileNotFound exception. This issue can be easily avoided by converting all Athena tables to use Symlink, ensuring a smoother and more reliable data consumption process.
Security
One of the most important aspects of Data management is security, and two aspects must be considered here – security at the infrastructure level and data security. Although, it’s a huge area to talk about, here are some of the practices that I have seen to be immensely useful.
Store secrets securely
While integrating with multiple systems, a common challenge is managing credentials. Access tokens to access these systems. Use the Databricks Secrets to store all your credentials and tokens securely and use Databricks Secrets in the notebooks. Databricks smartly redact any credentials from the notebook outputs.
Consider using/migrating to Unity Catalog
Unity Catalog is a unified data catalog and provides fine-grained access control and data lineage capabilities. With Unity Catalog, you don’t need to manage the access at individual buckets level and access can be managed in a more familiar SQL GRANT statement. Before deciding on Unity Catalog, consider the requirements to use its full potential; for example, switching to tables instead of data location in the code needs a mindset shift. Stay tuned for more in-depth discussion on the Unity Catalog, which will be published soon.
Conclusion
Databricks has changed the way we build data pipelines and projects, and it has unified Data Engineering, Ad-hoc Querying, and Data Governance aspects together in an easy-to-use environment that can be used by developers and data consumers alike. As with any tool, we need to play along with the prescribed and learned best practices. In this two-part blog series, I have shared the best practices around the four high-level areas – Operation Excellence, Reliability, Performance and Cost Optimization and Security. Of course, this by no means is a complete list and I can envision myself further expanding on these best practices and adding few more with a follow-up in the future.














