
AI is moving beyond ‘nice-to-have’ to becoming an essential part of modern digital systems. As we rely more and more on AI for decisions, it becomes absolutely essential to make sure that they are made ethically and free from unjust biases. We see a need for Responsible AI systems that are transparent, explainable, and accountable. At Persistent, we are actively building Responsible AI systems following the 5 tenets of Reproducibility, Transparency, Accountability, Security, and Privacy. Transparency is all about making systems explainable or interpretable and clearly measuring the amount and source of bias. In this article, we will focus on the transparency of AI systems, what it means to be fair and how to measure this.
What is the concept of Fairness & why is it important?
Fairness is a generic concept not restricted to AI. Any decision-making system can exhibit bias towards certain factors and thus, needs to be evaluated for fairness. Fairness here is tested by verifying if the bias is valid as per pre-established ethical principles. The legal definition of fairness is around the disparate treatment of and disparate impact to certain unpledged groups based on protected attributes like gender, race, religion, color, age, and more.
These attributes are defined by laws like Fair Credit Reporting Act (FCRA) which protects individuals from discrimination. Disparate treatment is when there is unlawful discrimination which is often handled strictly by laws like US labor law. Usually, Software systems fall in the disparate impact category where a neutral approach towards all has a disadvantageous effect on some people of a protected characteristic compared to others. Disparate impact is the negative effect an unfair and biased selection procedure has on a protected class.
It occurs when a protected group is discriminated against during a selection process, like a hiring or promotion decision. The legal approach to measure disparate impact is the Four-Fifths Rule which states that if the selection rate for a certain group is less than 80 percent of that of the group with the highest selection rate, there is an adverse impact on that group. Fairness may also be evaluated at an individual level where similar individuals are not treated in the same manner due to some unethical reason. We will look at some group fairness metrics and how to apply them in practice.
What is Bias and how do machines exhibit it?
Let’s take an example of human evaluation of student admissions. Say, you are manually deciding on the approval/rejection of students by reading the applications submitted. The application contains several factors like previous class grades, behavior comments, religion, age, family income, etc. If you base your decision on past grades of the student that is a bias and will mostly be considered fair. On another hand, if your decision is based on the gender of the applicant that bias may be considered unethical. There are often conflicting definitions of what is fair since it involves social-economic and human factors. For example, if we take family income as a deciding criterion, a bias based on that could be something that could spur a debate on whether it’s acceptable or not. Hence, fairness is not something you can crisply define in an ML pipeline and set thresholds in code; we usually show these fairness metrics to an AI ethics committee who decides the acceptability of the apparent bias.
Bias is something that our human brain exhibits when taking mental shortcuts or making assumptions to make decisions faster. Examples are confirmation bias where we focus on preconceived notions that certain fact is true. We often show a bandwagon effect and get influenced by decisions many others have made or we could fall for the gambler’s fallacy and get convinced that future probabilities are affected by past events. These are examples of human cognitive bias.
Machines also exhibit bias while making decisions. For a rule-based system, it’s easy to look at the steps of the algorithm and understand how decisions are made. It’s easy to find any existence of unwanted bias here since these systems are intrinsically explainable. When it comes to AI/ML systems the bias becomes difficult to find and explain since these systems usually learn patterns by finding correlations in the training data provided. The common source of bias for AI/ML systems in presence of bias in training data that flows into the ML model or there may be implementation issues while building the model that may cause bias to be induced. Let’s look at these two types of common Machine bias.
Types of Biases in AI
- Data Bias
Data bias can exist in training data usually due to historical bias in the system that flows directly in the collected data. For example, if historically male applicants have a greater selection rate for a job this bias will reflect directly in the data. Bias is not always due to historical reasons. Sometimes depending on the way training data is sampled from the population some sampling bias may be induced. For example, if we only select samples where male applicants were successful and females were not, then the trained model may incorrectly incorporate this bias.
- Confirmation Bias: Confirmation bias is when we collect data specifically with a predetermined assumption in mind. For example, if we want to prove that a treatment works for disease and only collect samples where it has worked.
- Algorithmic Bias
Not all bias is due to data though. Correlation fallacy is an algorithmic bias where we see a correlation in data and assume causation. Here there may be the presence of confounding factors that cause a condition and also affect the observed factors we collect. Hence the experimenter may incorrectly attribute the observed factors to cause the effect seen. Another example of algorithmic bias is labeling errors causing the model to learn incorrect patterns.
Let’s look at some examples of biased AI systems that have created headlines.
Case Study #1: Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) Software
The classic case is ProPublica’s analysis of Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) software. COMPAS was extensively used by the US Justice department to predict recidivism of crime by individuals based on 137 questions that are either answered by defendants or pulled from criminal records. COMPAS is a black-box proprietary system developed by Northpointe and we don’t really know how it makes the decision that could cause defendants to be jailed.
The study by ProPublica showed that this algorithm was biased, and black offenders were seen almost twice as likely as white offenders to be labeled a higher risk but not actually re-offend. This was a very popular and highly discussed study in news and clearly highlighted the need to have systems that are explainable and fair.
Case Study #2: Amazon
Another example is the AI-based recruiting tool used by Amazon that rated male candidates favorably compared to females. Here Amazon did not use any protected attribute (race, gender, age) in the decision-making process. However, since historically this bias existed in the data that was collected it reflected in the algorithm. This proves a major point that fairness through unawareness doesn’t work. You cannot ignore protected attributes and assume your algorithm will not show bias.
Fairness Metrics in AI
There are many definitions of fairness and as we saw earlier, they often conflict with each other. The definition you choose depends on the context in which the decision is being made. Let’s look at some definitions and corresponding metrics.
- Fairness through Unawareness
This is the classic definition where you omit the protected attributes from the calculation and assume the model will be fair. As we saw in the Amazon case study this doesn’t work. Many other features are intrinsically related to protected attributes like gender and race and the bias creeps up in your model. - Demographic parity
Here the focus is on equalizing the selection rate between privileged and unprivileged groups. Here the likelihood of a positive outcome should be the same regardless of whether the person is in the protected group. This definition is expressed through the following 2 metrics commonly used:
- Disparate impact ratio: the ratio of the rate of a favorable outcome for the unprivileged group to that of the privileged group.
- Statistical parity difference: the difference in the rate of favorable outcomes received by the unprivileged group to the privileged group.
- Equal opportunity
This and the next metric focuses not only on selection rate but also on the predictive power of the model. For equal opportunity, the focus is on trying to get the same true positive rate across groups. The probability of a person in a positive class being assigned to a positive outcome should be equal for both protected and unprotected (female and male) group members. - Equalized odds
Here the focus is on trying to get a same true positive rate as well as false positive rate across groups. Probability of a person in the positive class being correctly assigned a positive outcome and the probability of a person in a negative class being incorrectly assigned a positive outcome should both be the same for the protected and unprotected (male and female) group members.
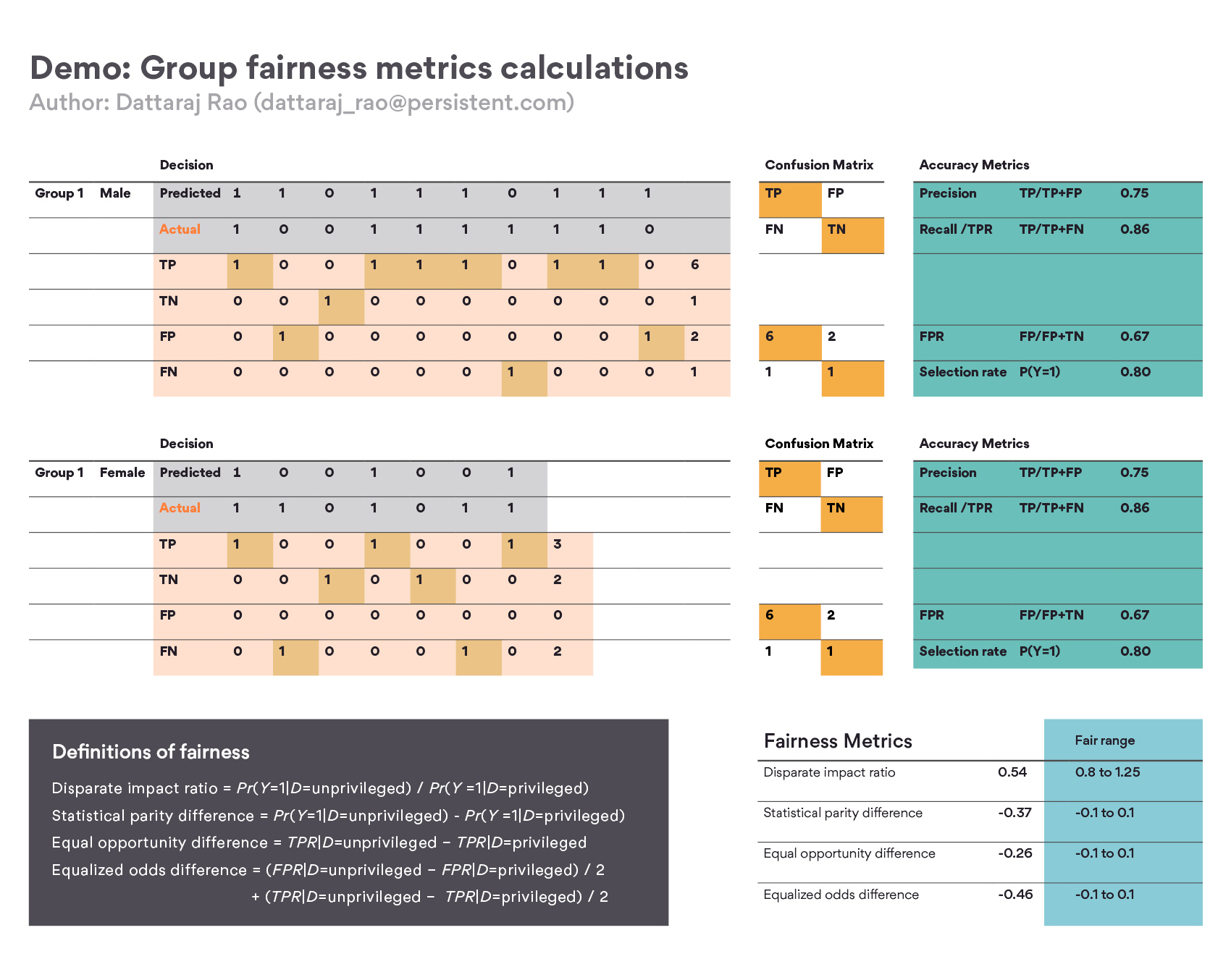
Many open-source libraries like Google’s What-if tool and IBM AI Fairness 360 can quickly calculate these metrics for you given the data and classifier. However, to better understand the calculations, let’s see how these fairness metrics are calculated by hand. The excel sheet shown below describes these metrics in detail and shows how these can be calculated. It is self-explanatory and available for download here. The sheet defines a scenario where the classification of two groups is compared by showing predicted vs actual values. Then constructing a confusion matrix, four fairness metrics are calculated.
At Persistent, we have provided our Customers with a Responsible AI framework that helps transform existing ML pipelines to analyze concerns like bias measurement, explainability & interpretability, data & concept drift analysis, generate audit reports, etc. The framework helps you build AI systems that are robust, ethical, and accountable. Learn more about Persistent’s Artificial Intelligence & Machine Learning Offerings. For more information or to understand how we can help your business connect with us at: airesearch@persistent.com
References
- AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias – Bellamy et al.
Learn more - Bias, Fairness, and Accountability with AI and ML Algorithms – Zhou et al.
Learn more - How We Analyzed the COMPAS Recidivism Algorithm
Learn more - A Survey on Bias and Fairness in Machine Learning – Mehrabi et al.
Learn more - AI Fairness Isn’t Just an Ethical Issue
Learn more



Find more content about
AI Systems (1) AI Metrics (1) Types of biases (1) AI Technology (1) AI Applications (1)


