
In our last blog we understood why enterprises are using Knowledge Graphs and their practical application across various industries. In this second blog installment, we will learn about the value proposition of Knowledge Graphs, their definition, when exactly are they used and how to create them. We will also go through an example to understand how Knowledge Graphs work!
Enterprises globally are trying to keep pace with the ever-evolving data needs. They often leverage organizational data to gain business insights, however, to achieve this, accurate processing of data becomes imperative. Given the sheer volume, multiple sources, and complexity of the data; bringing context to existing organizational data for creating intelligent insights is difficult to achieve.
To counter these challenges, Knowledge Graphs utilize Natural Language Processing, Machine Learning and Semantics to go through the structured and unstructured database to give us well-researched and explainable decisions.
Understanding the Value Proposition of Knowledge Graphs:
- Context: Knowledge Graphs provide context to algorithms by integrating different types of information into an ontology and are flexible to add newly derived knowledge on the go. It’s interesting to note that most traditional Knowledge Graphs can use various types of raw data simultaneously.
- Efficiency: Once desired entities and relations are available; Graphs offer computational efficiencies for querying stored data, resulting into an effective use of existing data for generating insights.
- Explainability: The large networks of entities and relations provide a great solution for the issue of understandability by integrating the meaning of entities available within the Graph itself. Owing to this, Knowledge Graphs become intrinsically explainable.
Defining Knowledge Graphs
Knowledge Graphs are an interlinked explanation of entities that deliver contextually relevant connected data. As per Gartner Top 10 Data and Analytics Trends for 2021, Graph forms the foundation of modern data and analytics with capabilities to enhance and improve user collaboration, Machine Learning models and Explainable AI.
Essentially, we can define a Knowledge Graph as
- It describes real world entities of a domain
- Provides relationship between them
- Defines rules for possible classes of entities and relations via some schema
- Enables reasoning to infer new knowledge
Features of Knowledge Graphs
Knowledge Graphs are self-descriptive as they provide a single place to find the data and understand what it is all about. They transition data into insightful knowledge!
However, please note Knowledge Graphs can be
- Auto generated or human curated
- Designed with a rigid ontology or may be evolving with time
- Existing in different shapes and sizes
- Developed by a company or by open source community
Irrespective of these differences, Knowledge Graphs help in organizing unstructured data in such a way that information can be easily extracted where explicit relations between multiple entities exist and contribute to the process.
Knowledge Graphs in Action
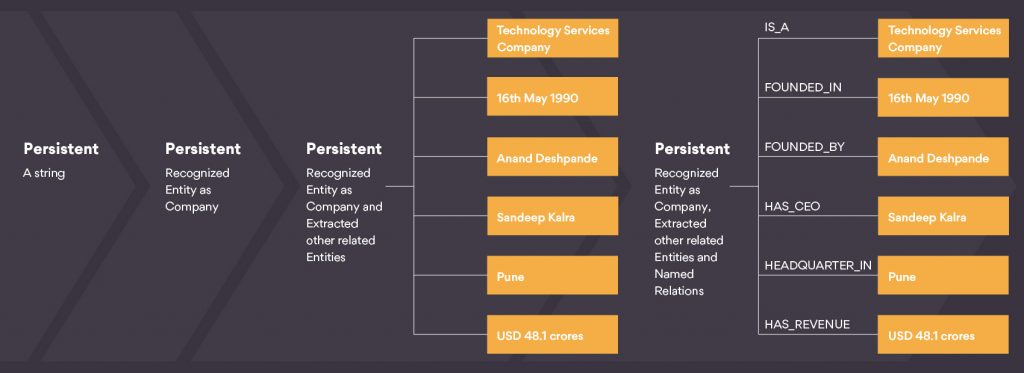
The final aim of a Knowledge Graph is to extract entities & relations and store them in the form of a triple: Subject-Predicate-Object. For example in the above image, the triples ‘Persistent Systems’-‘IS_A’-‘Technology Services Company’, ‘Persistent Systems’-‘FOUNDED_IN’-‘16 May 1990’, ‘Persistent Systems’-‘FOUNDED_BY’-‘Anand Deshpande’, ‘Persistent Systems’-‘HAS_CEO’-‘Sandeep Kalra’, etc. are all connecting two entities via a relation of a different type.
Beyond extracting entities, relations, and attributing information to display data, these interconnected units of knowledge actually encompass multiple other features on the route.
For example, it helps in normalizing data, enables acronym expansion, disambiguates similar entities, and connects entities to their data sources. To summarize, it helps in maintaining the overall data quality before ingesting data into the database for downstream applications to take advantage of the Knowledge Graphs for search and querying.
Utilizing Knowledge Graphs
There could be many reasons for implementing Knowledge Graphs. One of most important reasons to utilize Knowledge Graphs is the existence of loads of unstructured data originating from a variety of sources. This data may have changed over period of time to actually fit in a regular RDMS system.
There are multiple kinds of entities which are highly interlinked and there is a clear need for traversing many relationships quickly and frequently in order to derive insights for any business decision making.
A viable Knowledge Graph solution is closely linked to the business model & domain of the solution and hence, should always have a good coverage of relevant sources of information while building.
Connected data, enriched with meaning, allows for multiple interpretations of the same data. This is helpful for getting answers of complex queries to derive insights with better efficiency.
Creating Knowledge Graphs
Knowledge Graphs can be created manually or automatically, they can be open sources or complete proprietary solutions. The whole process of creating a Knowledge Graph from unstructured or structured data may have variations as per the domain and ultimate use of it. To explain this in a better way, we have presented a reference pipeline in the figure below.
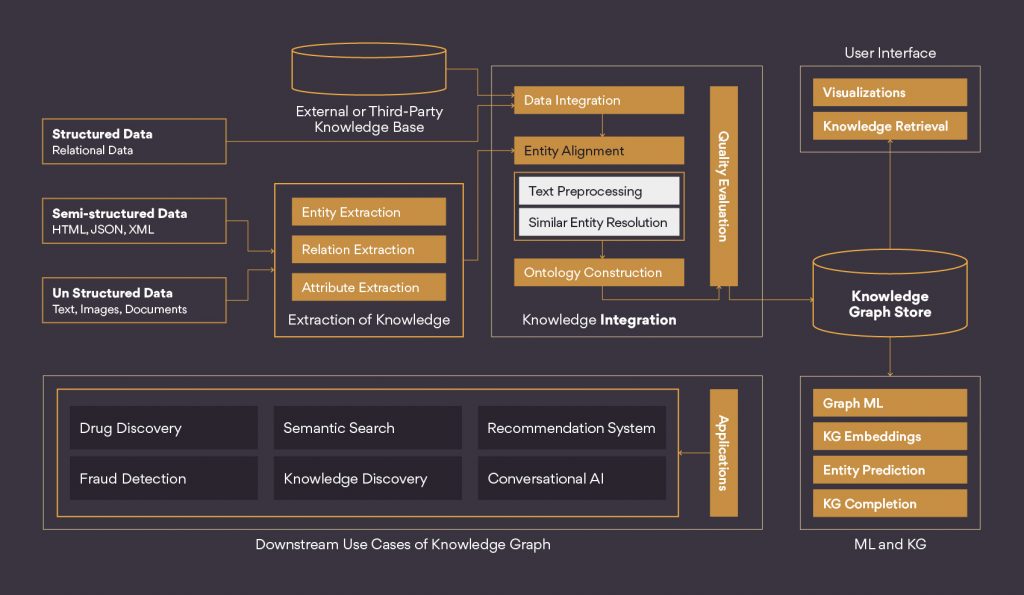
The above-mentioned reference pipeline will require a systematic use of Machine Learning, Natural Language Processing techniques and Integration at every stage. At Persistent, we are using this pipeline to develop some of the coolest solutions based on Knowledge Graphs for the Health Care and Banking & Finance Industries. To learn more about Persistent’s Artificial Intelligence & Machine Learning offerings, connect with us at: airesearch@persistent.com.





