The frenzy around Generative AI (GenAI) appears to be simmering as executive leaders look beyond sandboxes to scalable implementations that trigger end-to-end business transformation. A BCG report states that 66% of executives are ambivalent or outright dissatisfied with the progress their organization has made on GenAI. While GenAI has shown the potential to transform point use cases, enterprises still need to work around an executive trust deficit stemming from model inaccuracy, hallucination, and cognitive nonsense, among other issues —all tying back to AI explainability (See Figure 1).
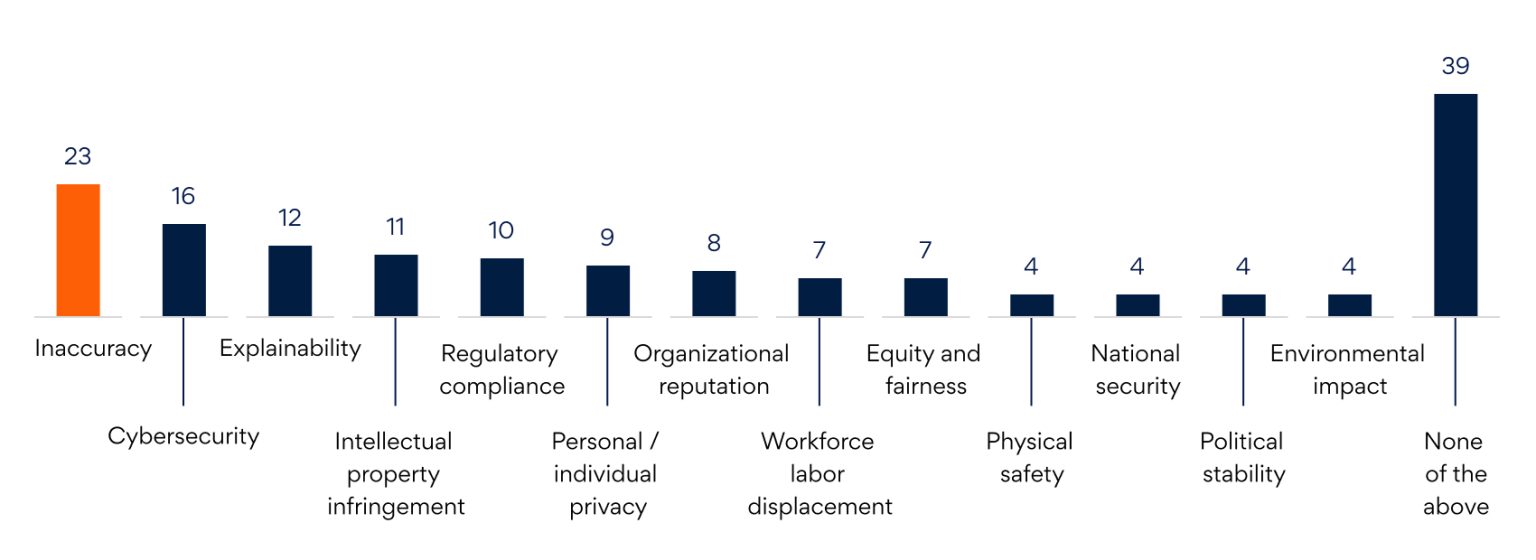
Until now, large language models (LLMs) powering GenAI use cases were trained on specific data sets, culled from larger unstructured data dumps, that could only address parts of a workflow or business domain. If user queries steer too far from the context of the training set, the model throws up inaccuracies or hallucinates. With enterprise data existing in silos across multiple systems and formats, it is difficult to integrate into a cohesive data architecture for the underlying LLM to work with. Due to data silos, the model also cannot provide causal reasoning for its output, resulting in low data utilization that renders GenAI systems unexplainable, and at best, black-boxed.
Knowledge Graphs: Unlocking Context, Data Relationships, and AI Explainability
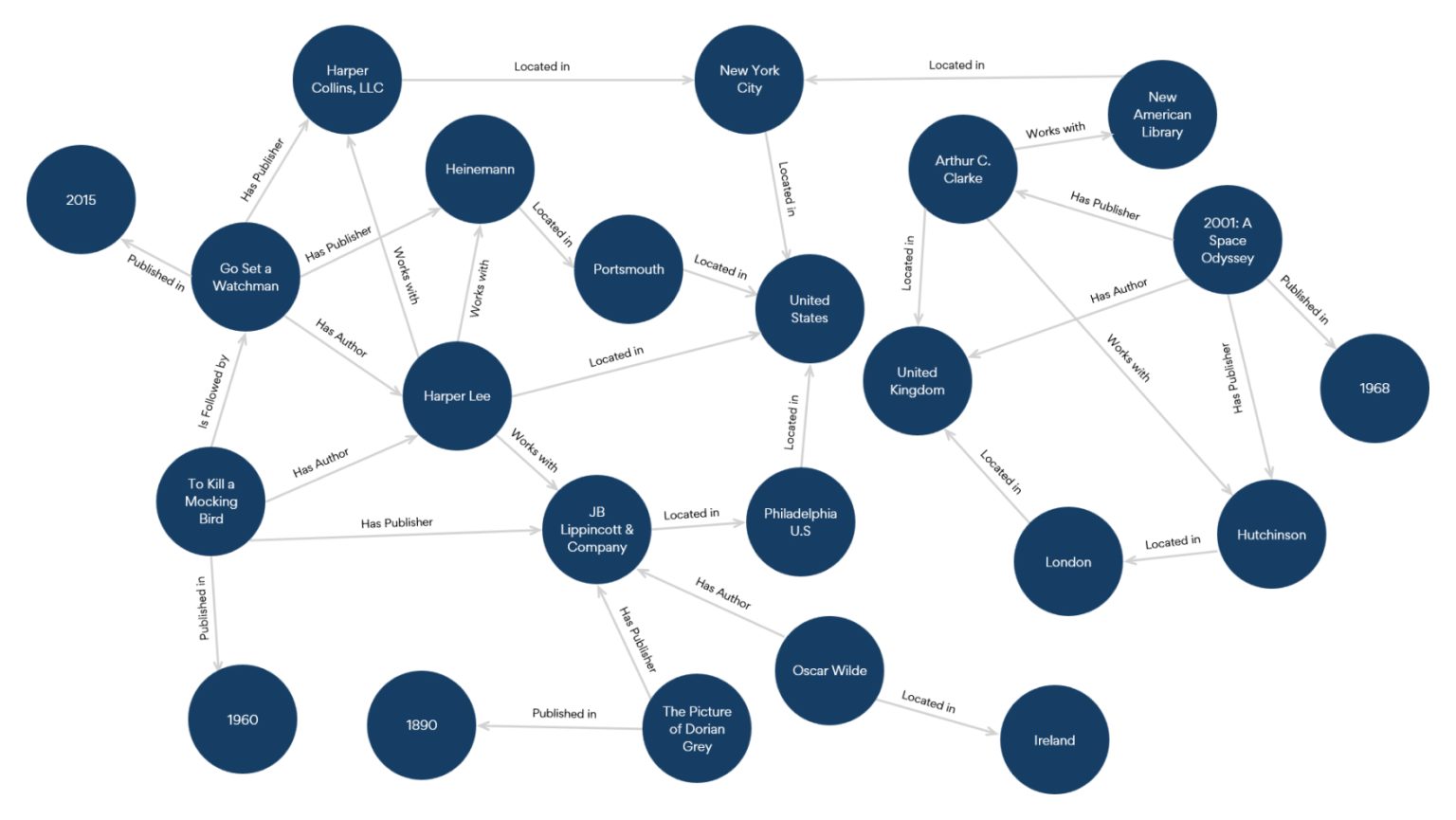
Knowledge graphs are semantic data models that integrate unstructured and structured data sets to capture the meaning, context, and relationships of entities and concepts within data. They are a network of nodes and edges, where nodes are entities or concepts, and edges are semantic links or properties that connect them (See Figure 2). As a graphical representation of data with dotted lines to denote inherent linkages, knowledge graphs mimic the neural network learning patterns of a human brain. Knowledge graphs can be used to ground LLMs, so the output follows Responsible AI principles and is more accurate, explainable, context-aware.
Knowledge graphs have existed for as long as AI explainability has been an issue. With GenAI, however, their usage becomes critical as enterprises scale GenAI systems internally and externally. Knowledge graphs have the potential to trigger GenAI-powered business transformation with:
- Enhanced data utilization: Since knowledge graphs integrate across siloed enterprise data sets, they enable the overlaid LLM to identify synergies or gaps and extract semantic relationships between various entities to provide a richer and more contextual output while explaining the reasoning or underlying causality. A loosely knotted data architecture improves data utilization, helping enterprises derive deeper insights from disparate data sets.
- Rapid inference: Since a knowledge graph represents data as nodes and associated dependencies as edges, it is easier for the LLM to make faster inferences that cut across data sets — borne out of a deeper understanding of the variables that interact with and influence each other. It becomes easier for the model to underline its output with more context, identify relationships that otherwise were hidden, and offer analyses efficiently.
- Accelerated model deployment: As a platform offering richer data relationships across enterprise data sets, knowledge graphs can train multiple LLMs across use cases without the heavy lifting required for individual models, significantly reducing the cost and effort overheads to deploy GenAI models.
- Improved GenAI adoption: Knowledge graphs can ground LLM output in Responsible AI principles so that they handle more complex queries about information stored in disparate data sets. They can also back up the answers with context, facts, and underlying relationships that help non-technical users make sense of highly technical information — thereby boosting adoption.
- Better collaboration: With a bird’s-eye view, LLMs can enable enterprise users with ready insights that foster enhanced cross-departmental collaboration, speed up innovation, enable accurate prediction models, empower teams to make more informed decisions, and instill better alignment between adjacent teams.
Power Enterprise-Wide GenAI Implementation: Bringing Knowledge Graphs to Life
While knowledge graphs do the patching, the elemental data must still be relevant and high-quality. Enterprises need to lay the groundwork by identifying the right data sets for use cases and consolidating them across modalities and formats into a cohesive data architecture.
As with any other AI model training, enterprises must invest in building data pipelines, defining the ontology or taxonomy, and determining the foundational relationships or domains under which they rest. Doing this on an enterprise scale can be complex, and it becomes even more so when LLMs need to self-learn with dynamic knowledge, which requires constantly adding new data sources to the underlying data architecture.
To abstract this complexity down to a click of a button, Persistent partners with Neo4j, a leading graph data platform, to enable enterprises to build knowledge graphs with minimal heavy lifting. This partnership brings together Persistent’s three decades of data science expertise with Neo4j’s industry-leading graph technology to set up underlying data architectures and graph platforms to turbocharge GenAI systems, with outputs that are explainable, trustworthy, and scalable. (To learn more about our partnership, watch this video here.)
To put it all together, we work with Amazon Web Services (AWS) to leverage its pre-trained LLMs, which our clients using knowledge graphs can utilize to execute more niche domain tasks. For instance, we deployed a knowledge graph-based GenAI model to understand how drug-to-drug combinations work or don’t work for cancer patients. Our knowledge graph factored in 47,031 nodes of 11 types and 2,250,197 relationships of 24 types to reveal common pathways shared by interacting drugs, facilitated biomarker discovery, and rationalized drug combinations. By harnessing the power of AI-ML and natural language processing (NLP) alongside data sciences, we transformed business processes to track drug interactions — helping us predict inherent risks in drug cocktails and contribute to an active area of translational oncology research.
We have built a GraphRAG solution (Graphs + Retrieval Augmented Generation) for Neo4j that automates the creation of knowledge graphs from any document uploaded or stored on Amazon S3. The graphs can be populated in Neo4j’s AuraDB or AWS Neo4j instance for access and analysis by By leveraging Neo4j Graph Data Science (GDS) library. We can also connect this to AWS Bedrock to run LLMs like Anthropic Claude3 with the graph data as grounding information.
For more details, click here, and to learn more about our work with knowledge graphs to understand drug-to-drug interactions, download our whitepaper here.
Author’s Profile

Dattaraj Rao
Chief Data Scientist, AI Research Lab





