
Introduction:
As collection of data gets automated, shouldn’t processing and extracting insights from that data be automated too? This article describes the need for developing a solution that does just that and touches upon the NLP and Deep Learning-based approach best taken to achieve it.
Such a solution has the potential to accelerate the evaluation of unstructured data with a view to improve business processes. Automating text extraction, text summarization and taxonomy-based search over tons of historical data can massively speed up business processes from hours to mere minutes.
Most businesses on the face of the earth could use a solution like this! But for the purpose of this blog, let’s focus on a very specific use case.
Example use case:
Let’s settle on an example from presales. This is what a typical presales cycle looks like.
The customer comes up with an innovative new idea and sends in a request for a proposal. At this point, senior management contacts the presales team and requests them to come up with something, usually ASAP. This is when presales tries to identify relevant people, talk with each of them and scan for similar work done in the past within tons of previous proposals, case studies etc. After all this manual work, the team stitches together a deck which can be presented to the customer. Most of the times, the team is required to tailor an offering to fit with the customer’s expectations.
The ideal solution is to have an intelligent search-based solution which can shorten the presales cycle and improve efficiency by providing an easily searchable list of historical case studies, complete with a short summary. This can deliver a customer-focused offering deck in minutes.
However, to achieve this easily, one must ensure that certain essential features are present in the solution.
Important features of the solution:
- Ability to index various document types – such as pdf, word, video, audio – and provide a taxonomy and semantic-based efficient search to find relevant documents from the existing repository.
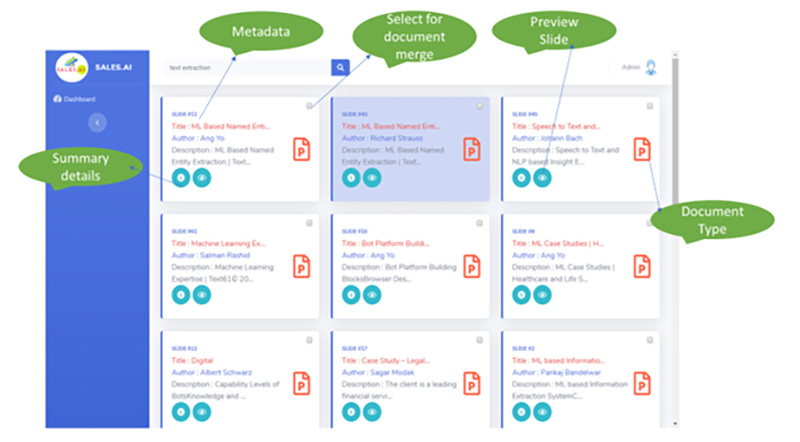
- Provide a summary of each search result with ranking in terms of relevance along with metadata like author, date, content type etc.
- Ability to merge different search results and create a new presentation with a click.
- Classification of documents to business verticals and technology horizontals.
- Lightweight application that can be integrated with other enterprise solutions on-premise/cloud.
System Design:

Technical details of each component:
- Text Extraction– For extraction of data and meta-data from documents, Apache Tika is used. For extraction from Video files, python module- FFMPEG is used to convert video to audio files, further, Google translate API is used to get text information from audio files.
- Text Punctuation– In case of text from audio, text punctuation is required to achieve the desired accuracy in extraction. The Europarl module is used for the same.
- Data Ingestion– Spring scheduler, which is basically a directory watcher service to monitor add/update the source document directory, is used.
- Text Summarization– Apache OpenNLP is used to summarize text from documents. Python NLTK module is used to summarize punctuated text from video/audio files.
- Document Classification– Weka framework is used to classify the documents into business verticals and technology horizontals.
- Data Indexing and Search– Apache Lucene is used to index text files from documents and video files. User search queries are served using the same index. Semantic and taxonomy-based search are supported.
- Web application– Built using Spring boot and Spring security. Bootstrap and jQuery are used primarily to build the UI/UX features. Word Cloud is also generated using Word Cloud python module.
- Document Merging– Helps to merge slides from different decks using selection on UI. This is achieved using Apache POI.
Sample User Interface:
Conclusion:
The sales process is one of the most important use cases to demonstrate the need of such a solution. Other use cases where such a solution can be relevant could be for physicians searching past clinical reports, lawyers looking for relevant historical cases, Ph.D. scholars researching topics of their study etc.
This solution approach/design can be implemented within weeks and can start helping improve business processes. The most exciting part is that since this solution only uses open-source tools and technologies, no licensing cost is involved in the development and maintenance of the solution.



Find more content about
AI research (1) Automated Solution (1) historical data (1) NLP Research (1) Open AI (1)


